本文共 11310 字,大约阅读时间需要 37 分钟。
JavaScript 高级

在线地址:
基本概念复习
由于 JavaScript 高级还是针对 JavaScript 语言本身的一个进阶学习,所以在开始之前我们先对以前所学过的 JavaScript 相关知识点做一个快速复习总结。
重新介绍 JavaScript
JavaScript 是什么
- 解析执行:轻量级解释型的,或是 JIT 编译型的程序设计语言
- 语言特点:动态,头等函数 (First-class Function)
- 又称函数是 JavaScript 中的一等公民
- 执行环境:在宿主环境(host environment)下运行,浏览器是最常见的 JavaScript 宿主环境
- 但是在很多非浏览器环境中也使用 JavaScript ,例如 node.js
- 编程范式:基于原型、多范式的动态脚本语言,并且支持面向对象、命令式和声明式(如:函数式编程)编程风格
JavaScript 与浏览器的关系
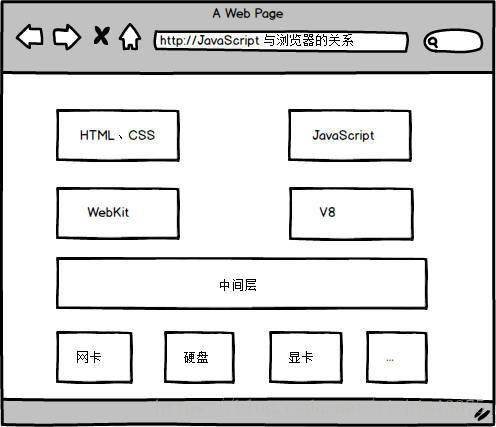
JavaScript 的组成
| 组成部分 | 说明 |
|---|---|
| Ecmascript | 描述了该语言的语法和基本对象 |
| DOM | 描述了处理网页内容的方法和接口 |
| BOM | 描述了与浏览器进行交互的方法和接口 |
JavaScript 可以做什么
Any application that can be written in JavaScript, will eventually be written in JavaScript.
凡是能用 JavaScript 写出来的,最终都会用 JavaScript 写出来
JavaScript 发展历史
- JavaScript 的诞生
- JavaScript 与 Ecmascript 的关系
- JavaScript 与 Java 的关系
- JavaScript 的版本
- JavaScript 周边大事记
小结
基本概念
本小节快速过即可,主要是对学过的内容做知识点梳理。
- 语法
- 区分大小写
- 标识符
- 注释
- 严格模式
- 语句
- 关键字和保留字
- 变量
- 数据类型
- typeof 操作符
- Undefined
- Null
- Boolean
- Number
- String
- Object
- 操作符
- 流程控制语句
- 函数
JavaScript 中的数据类型
JavaScript 有 5 种简单数据类型:Undefined、Null、Boolean、Number、String 和 1 种复杂数据类型 Object 。
基本类型(值类型)
- Undefined
- Null
- Boolean
- Number
- String
复杂类型(引用类型)
- Object
- Array
- Date
- RegExp
- Function
- 基本包装类型
- Boolean
- Number
- String
- 单体内置对象
- Global
- Math
类型检测
typeofinstanceofObject.prototype.toString.call()
值类型和引用类型在内存中的存储方式(画图说明)
- 值类型按值存储
- 引用类型按引用存储
值类型复制和引用类型复制(画图说明)
- 值类型按值复制
- 引用类型按引用复制
值类型和引用类型参数传递(画图说明)
- 值类型按值传递
- 引用类型按引用传递
值类型与引用类型的差别
- 基本类型在内存中占据固定大小的空间,因此被保存在栈内存中
- 从一个变量向另一个变量复制基本类型的值,复制的是值的副本
- 引用类型的值是对象,保存在堆内存
- 包含引用类型值的变量实际上包含的并不是对象本身,而是一个指向该对象的指针
- 从一个变量向另一个变量复制引用类型的值的时候,复制是引用指针,因此两个变量最终都指向同一个对象
小结
- 类型检测方式
- 值类型和引用类型的存储方式
- 值类型复制和引用类型复制
- 方法参数中 值类型数据传递 和 引用类型数据传递
JavaScript 执行过程
JavaScript 运行分为两个阶段:
- 预解析
- 全局预解析(所有变量和函数声明都会提前;同名的函数和变量函数的优先级高)
- 函数内部预解析(所有的变量、函数和形参都会参与预解析)
- 函数
- 形参
- 普通变量
- 执行
先预解析全局作用域,然后执行全局作用域中的代码,
在执行全局代码的过程中遇到函数调用就会先进行函数预解析,然后再执行函数内代码。JavaScript 面向对象编程
面向对象介绍
什么是对象
Everything is object (万物皆对象)

对象到底是什么,我们可以从两次层次来理解。
(1) 对象是单个事物的抽象。
一本书、一辆汽车、一个人都可以是对象,一个数据库、一张网页、一个与远程服务器的连接也可以是对象。当实物被抽象成对象,实物之间的关系就变成了对象之间的关系,从而就可以模拟现实情况,针对对象进行编程。
(2) 对象是一个容器,封装了属性(property)和方法(method)。
属性是对象的状态,方法是对象的行为(完成某种任务)。比如,我们可以把动物抽象为animal对象,使用“属性”记录具体是那一种动物,使用“方法”表示动物的某种行为(奔跑、捕猎、休息等等)。
在实际开发中,对象是一个抽象的概念,可以将其简单理解为:数据集或功能集。
ECMAScript-262 把对象定义为:无序属性的集合,其属性可以包含基本值、对象或者函数。
严格来讲,这就相当于说对象是一组没有特定顺序的值。对象的每个属性或方法都有一个名字,而每个名字都 映射到一个值。提示:每个对象都是基于一个引用类型创建的,这些类型可以是系统内置的原生类型,也可以是开发人员自定义的类型。
什么是面向对象
面向对象不是新的东西,它只是过程式代码的一种高度封装,目的在于提高代码的开发效率和可维护性。

面向对象编程 —— Object Oriented Programming,简称 OOP ,是一种编程开发思想。
它将真实世界各种复杂的关系,抽象为一个个对象,然后由对象之间的分工与合作,完成对真实世界的模拟。在面向对象程序开发思想中,每一个对象都是功能中心,具有明确分工,可以完成接受信息、处理数据、发出信息等任务。
因此,面向对象编程具有灵活、代码可复用、高度模块化等特点,容易维护和开发,比起由一系列函数或指令组成的传统的过程式编程(procedural programming),更适合多人合作的大型软件项目。面向对象与面向过程:
- 面向过程就是亲力亲为,事无巨细,面面俱到,步步紧跟,有条不紊
- 面向对象就是找一个对象,指挥得结果
- 面向对象将执行者转变成指挥者
- 面向对象不是面向过程的替代,而是面向过程的封装
面向对象的特性:
- 封装性
- 继承性
- [多态性]
扩展阅读:
程序中面向对象的基本体现
在 JavaScript 中,所有数据类型都可以视为对象,当然也可以自定义对象。
自定义的对象数据类型就是面向对象中的类( Class )的概念。我们以一个例子来说明面向过程和面向对象在程序流程上的不同之处。
假设我们要处理学生的成绩表,为了表示一个学生的成绩,面向过程的程序可以用一个对象表示:
var std1 = { name: 'Michael', score: 98 }var std2 = { name: 'Bob', score: 81 } 而处理学生成绩可以通过函数实现,比如打印学生的成绩:
function printScore (student) { console.log('姓名:' + student.name + ' ' + '成绩:' + student.score)} 如果采用面向对象的程序设计思想,我们首选思考的不是程序的执行流程,
而是Student 这种数据类型应该被视为一个对象,这个对象拥有 name 和 score 这两个属性(Property)。 如果要打印一个学生的成绩,首先必须创建出这个学生对应的对象,然后,给对象发一个 printScore 消息,让对象自己把自己的数据打印出来。 抽象数据行为模板(Class):
function Student (name, score) { this.name = name this.score = score}Student.prototype.printScore = function () { console.log('姓名:' + this.name + ' ' + '成绩:' + this.score)} 根据模板创建具体实例对象(Instance):
var std1 = new Student('Michael', 98)var std2 = new Student('Bob', 81) 实例对象具有自己的具体行为(给对象发消息):
std1.printScore() // => 姓名:Michael 成绩:98std2.printScore() // => 姓名:Bob 成绩 81
面向对象的设计思想是从自然界中来的,因为在自然界中,类(Class)和实例(Instance)的概念是很自然的。
Class 是一种抽象概念,比如我们定义的 Class——Student ,是指学生这个概念, 而实例(Instance)则是一个个具体的 Student ,比如, Michael 和 Bob 是两个具体的 Student 。所以,面向对象的设计思想是:
- 抽象出 Class
- 根据 Class 创建 Instance
- 指挥 Instance 得结果
面向对象的抽象程度又比函数要高,因为一个 Class 既包含数据,又包含操作数据的方法。
创建对象
简单方式
我们可以直接通过 new Object() 创建:
var person = new Object()person.name = 'Jack'person.age = 18person.sayName = function () { console.log(this.name)} 每次创建通过 new Object() 比较麻烦,所以可以通过它的简写形式对象字面量来创建:
var person = { name: 'Jack', age: 18, sayName: function () { console.log(this.name) }} 对于上面的写法固然没有问题,但是假如我们要生成两个 person 实例对象呢?
var person1 = { name: 'Jack', age: 18, sayName: function () { console.log(this.name) }}var person2 = { name: 'Mike', age: 16, sayName: function () { console.log(this.name) }} 通过上面的代码我们不难看出,这样写的代码太过冗余,重复性太高。
简单方式的改进:工厂函数
我们可以写一个函数,解决代码重复问题:
function createPerson (name, age) { return { name: name, age: age, sayName: function () { console.log(this.name) } }} 然后生成实例对象:
var p1 = createPerson('Jack', 18)var p2 = createPerson('Mike', 18) 这样封装确实爽多了,通过工厂模式我们解决了创建多个相似对象代码冗余的问题,
但却没有解决对象识别的问题(即怎样知道一个对象的类型)。构造函数
内容引导:
- 构造函数语法
- 分析构造函数
- 构造函数和实例对象的关系
- 实例的 constructor 属性
- instanceof 操作符
- 普通函数调用和构造函数调用的区别
- 构造函数的返回值
- 构造函数的静态成员和实例成员
- 函数也是对象
- 实例成员
- 静态成员
- 构造函数的问题
更优雅的工厂函数:构造函数
一种更优雅的工厂函数就是下面这样,构造函数:
function Person (name, age) { this.name = name this.age = age this.sayName = function () { console.log(this.name) }}var p1 = new Person('Jack', 18)p1.sayName() // => Jackvar p2 = new Person('Mike', 23)p2.sayName() // => Mike 解析构造函数代码的执行
在上面的示例中,Person() 函数取代了 createPerson() 函数,但是实现效果是一样的。
我们注意到,Person() 中的代码与 createPerson() 有以下几点不同之处:
- 没有显示的创建对象
- 直接将属性和方法赋给了
this对象 - 没有
return语句 - 函数名使用的是大写的
Person
而要创建 Person 实例,则必须使用 new 操作符。
- 创建一个新对象
- 将构造函数的作用域赋给新对象(因此 this 就指向了这个新对象)
- 执行构造函数中的代码
- 返回新对象
下面是具体的伪代码:
function Person (name, age) { // 当使用 new 操作符调用 Person() 的时候,实际上这里会先创建一个对象 // var instance = {} // 然后让内部的 this 指向 instance 对象 // this = instance // 接下来所有针对 this 的操作实际上操作的就是 instance this.name = name this.age = age this.sayName = function () { console.log(this.name) } // 在函数的结尾处会将 this 返回,也就是 instance // return this} 构造函数和实例对象的关系
使用构造函数的好处不仅仅在于代码的简洁性,更重要的是我们可以识别对象的具体类型了。
在每一个实例对象中的__proto__中同时有一个constructor 属性,该属性指向创建该实例的构造函数: console.log(p1.constructor === Person) // => trueconsole.log(p2.constructor === Person) // => trueconsole.log(p1.constructor === p2.constructor) // => true
对象的 constructor 属性最初是用来标识对象类型的,
instanceof 操作符更可靠一些: console.log(p1 instanceof Person) // => trueconsole.log(p2 instanceof Person) // => true
总结:
- 构造函数是根据具体的事物抽象出来的抽象模板
- 实例对象是根据抽象的构造函数模板得到的具体实例对象
- 每一个实例对象都具有一个
constructor属性,指向创建该实例的构造函数- 注意:
constructor是实例的属性的说法不严谨,具体后面的原型会讲到
- 注意:
- 可以通过实例的
constructor属性判断实例和构造函数之间的关系- 注意:这种方式不严谨,推荐使用
instanceof操作符,后面学原型会解释为什么
- 注意:这种方式不严谨,推荐使用
构造函数的问题
使用构造函数带来的最大的好处就是创建对象更方便了,但是其本身也存在一个浪费内存的问题:
function Person (name, age) { this.name = name this.age = age this.type = 'human' this.sayHello = function () { console.log('hello ' + this.name) }}var p1 = new Person('lpz', 18)var p2 = new Person('Jack', 16) 在该示例中,从表面上好像没什么问题,但是实际上这样做,有一个很大的弊端。
那就是对于每一个实例对象,type 和 sayHello 都是一模一样的内容, 每一次生成一个实例,都必须为重复的内容,多占用一些内存,如果实例对象很多,会造成极大的内存浪费。 console.log(p1.sayHello === p2.sayHello) // => false
对于这种问题我们可以把需要共享的函数定义到构造函数外部:
function sayHello = function () { console.log('hello ' + this.name)}function Person (name, age) { this.name = name this.age = age this.type = 'human' this.sayHello = sayHello}var p1 = new Person('lpz', 18)var p2 = new Person('Jack', 16)console.log(p1.sayHello === p2.sayHello) // => true 这样确实可以了,但是如果有多个需要共享的函数的话就会造成全局命名空间冲突的问题。
你肯定想到了可以把多个函数放到一个对象中用来避免全局命名空间冲突的问题:
var fns = { sayHello: function () { console.log('hello ' + this.name) }, sayAge: function () { console.log(this.age) }}function Person (name, age) { this.name = name this.age = age this.type = 'human' this.sayHello = fns.sayHello this.sayAge = fns.sayAge}var p1 = new Person('lpz', 18)var p2 = new Person('Jack', 16)console.log(p1.sayHello === p2.sayHello) // => trueconsole.log(p1.sayAge === p2.sayAge) // => true 至此,我们利用自己的方式基本上解决了构造函数的内存浪费问题。
但是代码看起来还是那么的格格不入,那有没有更好的方式呢?小结
- 构造函数语法
- 分析构造函数
- 构造函数和实例对象的关系
- 实例的 constructor 属性
- instanceof 操作符
- 构造函数的问题
原型
内容引导:
- 使用 prototype 原型对象解决构造函数的问题
- 分析 构造函数、prototype 原型对象、实例对象 三者之间的关系
- 属性成员搜索原则:原型链
- 实例对象读写原型对象中的成员
- 原型对象的简写形式
- 原生对象的原型
- Object
- Array
- String
- …
- 原型对象的问题
- 构造的函数和原型对象使用建议
更好的解决方案: prototype
Javascript 规定,每一个构造函数都有一个 prototype 属性,指向另一个对象。
这也就意味着,我们可以把所有对象实例需要共享的属性和方法直接定义在 prototype 对象上。
function Person (name, age) { this.name = name this.age = age}console.log(Person.prototype)Person.prototype.type = 'human'Person.prototype.sayName = function () { console.log(this.name)}var p1 = new Person(...)var p2 = new Person(...)console.log(p1.sayName === p2.sayName) // => true 这时所有实例的 type 属性和 sayName() 方法,
prototype 对象,因此就提高了运行效率。 构造函数、实例、原型三者之间的关系
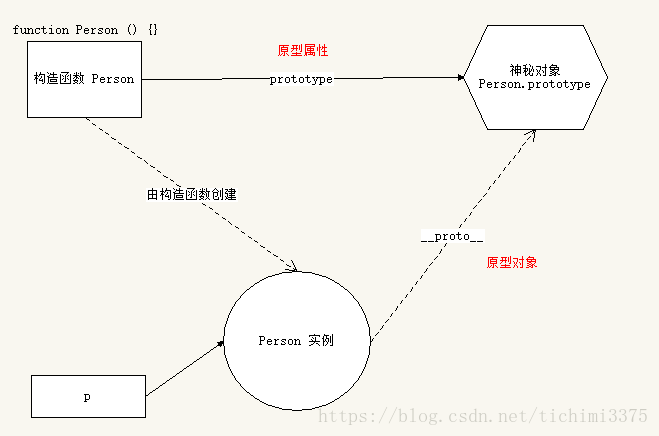
任何函数都具有一个 prototype 属性,该属性是一个对象。
function F () { }console.log(F.prototype) // => objectF.prototype.sayHi = function () { console.log('hi!')} 构造函数的 prototype 对象默认都有一个 constructor 属性,指向 prototype 对象所在函数。
console.log(F.constructor === F) // => true
通过构造函数得到的实例对象内部会包含一个指向构造函数的 prototype 对象的指针 __proto__。
var instance = new F()console.log(instance.__proto__ === F.prototype) // => true
`__proto__` 是非标准属性。
实例对象可以直接访问原型对象成员。
instance.sayHi() // => hi!
总结:
- 任何函数都具有一个
prototype属性,该属性是一个对象 - 构造函数的
prototype对象默认都有一个constructor属性,指向prototype对象所在函数 - 通过构造函数得到的实例对象内部会包含一个指向构造函数的
prototype对象的指针__proto__ - 所有实例都直接或间接继承了原型对象的成员
属性成员的搜索原则:原型链
了解了 构造函数-实例-原型对象 三者之间的关系后,接下来我们来解释一下为什么实例对象可以访问原型对象中的成员。
每当代码读取某个对象的某个属性时,都会执行一次搜索,目标是具有给定名字的属性
- 搜索首先从对象实例本身开始
- 如果在实例中找到了具有给定名字的属性,则返回该属性的值
- 如果没有找到,则继续搜索指针指向的原型对象,在原型对象中查找具有给定名字的属性
- 如果在原型对象中找到了这个属性,则返回该属性的值
也就是说,在我们调用 person1.sayName() 的时候,会先后执行两次搜索:
- 首先,解析器会问:“实例 person1 有 sayName 属性吗?”答:“没有。
- ”然后,它继续搜索,再问:“ person1 的原型有 sayName 属性吗?”答:“有。
- ”于是,它就读取那个保存在原型对象中的函数。
- 当我们调用 person2.sayName() 时,将会重现相同的搜索过程,得到相同的结果。
而这正是多个对象实例共享原型所保存的属性和方法的基本原理。
总结:
- 先在自己身上找,找到即返回
- 自己身上找不到,则沿着原型链向上查找,找到即返回
- 如果一直到原型链的末端还没有找到,则返回
undefined
实例对象读写原型对象成员
读取:
- 先在自己身上找,找到即返回
- 自己身上找不到,则沿着原型链向上查找,找到即返回
- 如果一直到原型链的末端还没有找到,则返回
undefined
值类型成员写入(实例对象.值类型成员 = xx):
- 当实例期望重写原型对象中的某个普通数据成员时实际上会把该成员添加到自己身上
- 也就是说该行为实际上会屏蔽掉对原型对象成员的访问
引用类型成员写入(实例对象.引用类型成员 = xx):
- 同上
复杂类型修改(实例对象.成员.xx = xx):
- 同样会先在自己身上找该成员,如果自己身上找到则直接修改
- 如果自己身上找不到,则沿着原型链继续查找,如果找到则修改
- 如果一直到原型链的末端还没有找到该成员,则报错(
实例对象.undefined.xx = xx)
更简单的原型语法
我们注意到,前面例子中每添加一个属性和方法就要敲一遍 Person.prototype 。
function Person (name, age) { this.name = name this.age = age}Person.prototype = { type: 'human', sayHello: function () { console.log('我叫' + this.name + ',我今年' + this.age + '岁了') }} 在该示例中,我们将 Person.prototype 重置到了一个新的对象。
Person.prototype 添加成员简单了,但是也会带来一个问题,那就是原型对象丢失了 constructor 成员。 所以,我们为了保持 constructor 的指向正确,建议的写法是:
function Person (name, age) { this.name = name this.age = age}Person.prototype = { constructor: Person, // => 手动将 constructor 指向正确的构造函数 type: 'human', sayHello: function () { console.log('我叫' + this.name + ',我今年' + this.age + '岁了') }} 原生对象的原型
所有函数都有 prototype 属性对象。
- Object.prototype
- Function.prototype
- Array.prototype
- String.prototype
- Number.prototype
- Date.prototype
- …
练习:为数组对象和字符串对象扩展原型方法。
原型对象的问题
- 共享数组
- 共享对象
如果真的希望可以被实例对象之间共享和修改这些共享数据那就不是问题。但是如果不希望实例之间共享和修改这些共享数据则就是问题。
一个更好的建议是,最好不要让实例之间互相共享这些数组或者对象成员,一旦修改的话会导致数据的走向很不明确而且难以维护。
原型对象使用建议
- 私有成员(一般就是非函数成员)放到构造函数中
- 共享成员(一般就是函数)放到原型对象中
- 如果重置了
prototype记得修正constructor的指向
案例:随机方块
title